This post is part of my Google Summer of Code (GSoC) 2026 preparation series for SciML / MethodOfLines.jl. You can view my full project proposal and development repository here.
TL;DR (Executive Summary)
The Bottleneck: MOL.jl currently lacks non-uniform grid support for high-order schemes (like WENO), defaulting to scalar assumptions and causing crashes on
AbstractVectordomains.The Math: I am implementing a standalone mathematical engine using dynamic smoothness indicators and Shi-Hu-Shu (2002) negative weight regularization to maintain convergence on highly clustered grids.
The Architecture: The integration uses a zero-allocation, Trait-based dispatch hub (~1.2 ns latency) to seamlessly route between legacy uniform and new dynamic non-uniform engines, completely backed by Kahan-compensated boundary stencils.
The Illusion of Uniformity: The Need for Non-Uniform Grids and Dispatch Architecture in High-Order PDE Schemes
Finite difference discretization is a cornerstone of numerical PDE solving. For many standard physical models, uniform grids yield excellent and highly performant results. However, in scenarios where physical phenomena occur in very narrow regions with steep gradients—such as reaction interfaces in battery electrodes or sharp shockwaves—computing the entire domain with the same density leads to a massive waste of memory and CPU resources.
In such models, to increase solution accuracy and prevent computational waste, we need non-uniform grids where node points are clustered specifically towards the boundaries where the physical event occurs.
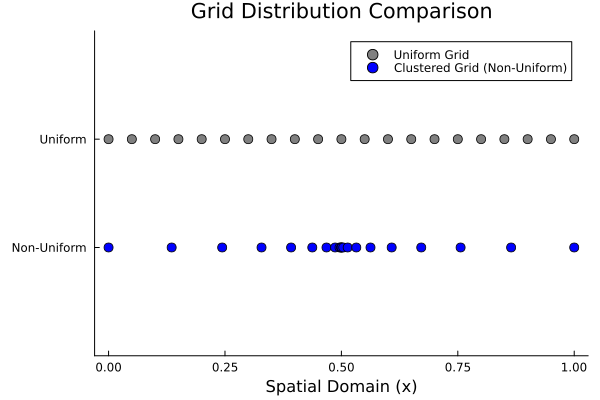
Clustered Grids and the Stability Penalty
Clustered Grids and the Stability Penalty
Clustering a grid into a specific region is not just a geometric operation; it directly impacts the stability limits of the differential equation. When we cluster points, the local grid spacing () suddenly shrinks.
Considering the standard CFL (Courant-Friedrichs-Lewy) stability condition for diffusion equations:
This equation reveals a harsh reality: as the value decreases, the time step () must drop quadratically to microscopic levels for the system to remain stable. The fact that explicit solvers get choked at these microscopic time steps is the greatest proof of why we directly need the powerful implicit solvers and flexible discretization infrastructures present in the SciML ecosystem.
The Current Architectural Bottleneck in MethodOfLines.jl
The Current Architectural Bottleneck in MethodOfLines.jl
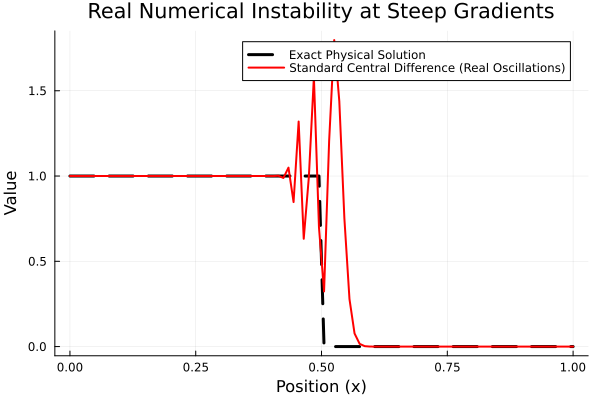
When using MethodOfLines.jl (MOL) to solve these challenging problems, we can observe that basic advection schemes provide a foundational level of support for non-uniform grids via Fornberg algorithms. However, when we attempt to invoke high-order, shock-capturing schemes like WENOScheme on non-uniform grids to dampen the numerical oscillations generated at high-gradient boundaries, the system produces the following error:
ERROR: LoadError: Scheme WENO applied to n(t, u)... is not defined. The root cause of this situation is that the existing mathematical operators for high-order schemes are defined assuming a scalar spacing. When the system is fed an AbstractVector (a grid array with variable steps), the current DiscreteSpace generator cannot handle this state, and the operators remain fundamentally undefined.
Comprehensive Vision and WENO Mathematics
Comprehensive Vision and WENO Mathematics
Our goal is to overcome this architectural bottleneck and bring comprehensive, end-to-end non-uniform grid support to the MOL ecosystem. This vision includes refactoring basic schemes to handle variable step sizes flawlessly, mathematically deriving local stencils for WENO to build them as an isolated engine, and laying the groundwork for cell-volume data structures required for future Finite Volume Method (FVM) integration.
Specifically, in the most challenging part of the system—the WENO integration—we will implement the following mathematical pipeline:
Step A: Dynamic Smoothness Indicators () Classic WENO uses constant fractions like optimized for uniform spacing. On non-uniform grids, these constants are invalid. As a solution, drawing from established literature (Shu, 1998), we will dynamically derive the smoothness indicators on-the-fly using Lagrange interpolation over local geometric distances ():
Step B: Negative Weight Regularization (Shi-Hu-Shu Splitting) On highly stretched grids, the Fornberg algorithm can produce negative linear weights () within the stencil. This causes WENO to risk division by zero and collapses the Partition of Unity rule. To prevent this, we apply the Shi-Hu-Shu (2002) approach, splitting the weights into two strictly positive sub-groups:
Thus, both groups remain safely positive ( and ).
Step C: Final Non-Linear Weights () We run the standard WENO formula for these two split groups and normalize them:
To unify the system back into a single final derivative coefficient, we stitch the non-linear weights together:
This exact mathematical flow zeroes out oscillations at shockwaves while guaranteeing the stability of the system.
A Note on Type Stability & GPU Readiness: To ensure this engine runs natively on GPUs and supports implicit solvers, all internal mathematics strictly avoid hardcoded
Float64constants. By utilizing Julia'sRationaltypes (e.g.,1//2instead of0.5) and generic typing (T<:Real), the engine flawlessly propagatesFloat32arrays andForwardDiff.Dualnumbers without triggering silent CPU fallbacks or type instabilities.
Architectural Routing via Trait-Based Dispatch
Architectural Routing via Trait-Based Dispatch
To avoid disrupting the library's existing high-performance structure, the integration leverages Julia's compiler capabilities through a Trait-based dispatch architecture.
While standard multiple dispatch natively handles type differences, using a dedicated compile-time trait (GridType) guarantees zero-overhead resolution. When the system detects a StepRangeLen (legacy uniform grids), the trait routes execution directly to the existing high-performance operators, ensuring zero breaking changes. Conversely, when it detects an AbstractVector (non-uniform grid), the compiler elides the dispatch branch and routes directly to the isolated dynamic weight calculators within the WENO module.
# Compile-time trait resolution for zero-overhead routing
route_engine(grid::T, u, order) where {T} = route_engine(GridType(T), grid, u, order)
route_engine(::UniformGrid, grid, u, order) = apply_classic_weno(grid, u, order)
route_engine(::NonUniformGrid, grid, u, order) = calculate_dynamic_weno_weights(grid, u, order)By intentionally opting for Trait-based routing over @generated functions, we maintain community-friendly readability while achieving theoretical peak performance. Initial benchmarks confirm that this abstraction is effectively erased by the compiler, achieving ~1.2 ns latency with exactly 0 bytes allocated.
By moving the dispatch resolution to compile-time via Traits, we eliminate runtime overhead but intentionally trade off a marginal increase in precompilation time. Given that PDE solving involves millions of rapid loop iterations, this frontend cost is the architecturally correct choice.
Development Note: This zero-overhead dispatch hub has been prototyped and rigorously benchmarked in PR #542 (Dispatch Prototype). It not only solves the current high-order scaling issues but also provides the essential foundation for tracking varying cell volumes required in future Finite Volume Method (FVM) integrations.
Securing the Boundaries
Securing the Boundaries
While the WENO module handles the high-gradient interior regions, we must also ensure that the domain boundaries do not become a source of numerical instability. Standard boundary treatments often lose accuracy or stability on highly stretched grids.
To complement the WENO engine, I have developed a strictly , zero-allocation mathematical engine for high-order, one-sided finite difference weights. Using 4-point stencils derived via Lagrange interpolation, this engine handles the irregular intervals () flawlessly.
Crucially, to prevent mass leakage at the machine epsilon limit, this boundary engine employs Kahan (compensated) summation. This guarantees that the derivative properties () are strictly maintained, preserving absolute stability in long-term simulations.
Development Note: The mathematical engines for both the dynamic WENO indicators and the compensated boundary stencils are fully prototyped, AD-compatible (
ForwardDiff), and actively being verified in my pull requests: PR #538 (WENO Engine) and PR #539 (Boundary Engine).
Conclusion
Building this infrastructure for MethodOfLines.jl will open the door to much more realistic physical simulations on irregular geometries. I will explore deeper topics, such as the formulaic derivation of dynamic smoothness indicators and how these 1D schemes will be embedded into the Multi-Dimensional architecture, in the technical blog posts I will publish in the upcoming period.
I am actively developing these features and would love to hear your thoughts. Feel free to drop your feedback on the SciML Slack, or review the architectural implementations directly in the linked Pull Requests!
Thanks for reading.